Generating the Generator
Recognition
M. Arch Thesis, Princeton University, Spring 2017
Selected for AI Art Online at NeurIPS 2018
The plan is the generator.
— Le Corbusier
Since 2012, deep learning has fundamentally changed the ways in which we analyze and create images. Though architects work in discrete, vector-based drawing and modeling tools, we all ultimately consume dense, pixelated representations on through social media, streaming platforms, and any image we see on our screens.
Is it possible to apply deep learning models to these representations to explore the latent space of our design and engineering documents? If, as Le Corbusier suggests, these drawings are generative of ideas, can we generate the generators?
I believe that it is possible and that we will increasingly see the application of generative machine learning models to explore early design ideas. However, we must also adapt our analytical tools to this regime to be able to create salient loss metrics that drive these models towards optima that minimize loss not in the rote quantitative sense, but that can enforce positive social and cultural values that must be considered in any building project.
Up to this point, most neural network research had focused on improving model performance on images with semantically different image content (e.g ImageNet’s categorical classifications). One of the primary contributions of this work is the application of the same models to semantically similar images, but with significant qualitative differences.
Methods
As all machine learning models must be fit to datasets, this investigation began with a collection of various datasets of architectural references.
Data subset
There are multiple “families” of references. The hypothesis was that these different subsets would act as qualitative “vectors” which would drive the generative models towards a certain family. These examples effectively act as points describing the subspaces that are in the style of:
- Medieval castles
- Works Progress Administration municipal buildings
- Le Corbusier
- Morphosis
- Frank Gehry
- Michael Graves
Though each of these examples has their own particular cultural, social, and political significance, the specific examples are not considered here for anything other than their easily recognizable qualitative differences.
When subject to deep neural network-based analytical models, they serve a similar purpose. That is, we would expect that a cogent analytical framework would be able to organize qualitative similar works closely in a target vector space (e.g., the restricted layer of an autoencoder) and would organize qualitatively disparate images distantly from one another.1
Image: 1 of 3
Analysis
Classification
An early experiment was performed on a small subset of the whole dataset which was manually cut into categories of common architectural elements to prove whether image classifiers could be trained to a meaningful accuracy on semantically-different but sparse images of the type that we would like to operate on at larger scales.
The five categories in question are:
- columns
- doors
- rooms
- stairs
- windows
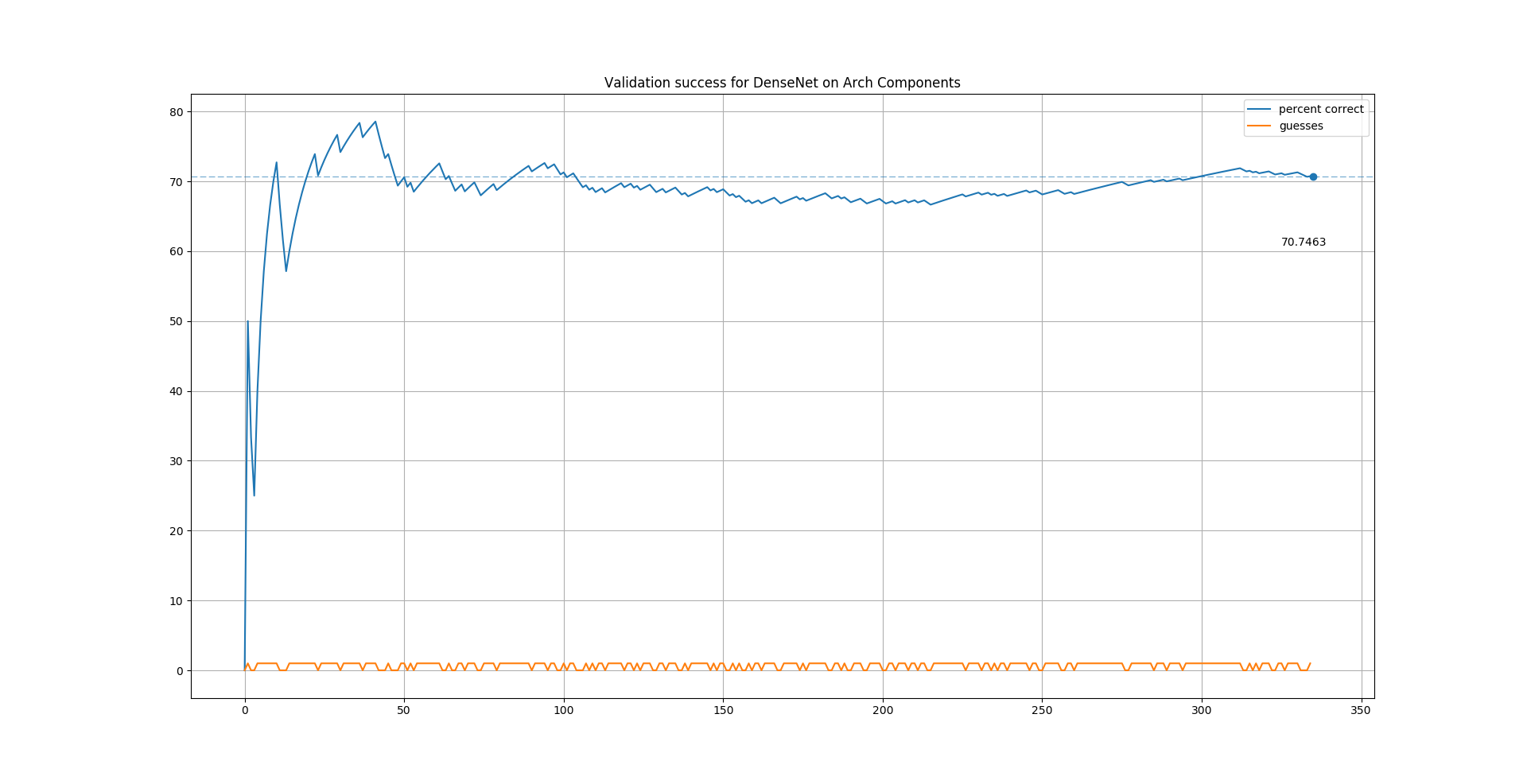
The highest performing classifier was densenet-121 which achieved a mean
validation accuracy of 70.75% using SGD and learning rate decay after transfer
learning from a base model trained on ImageNet.
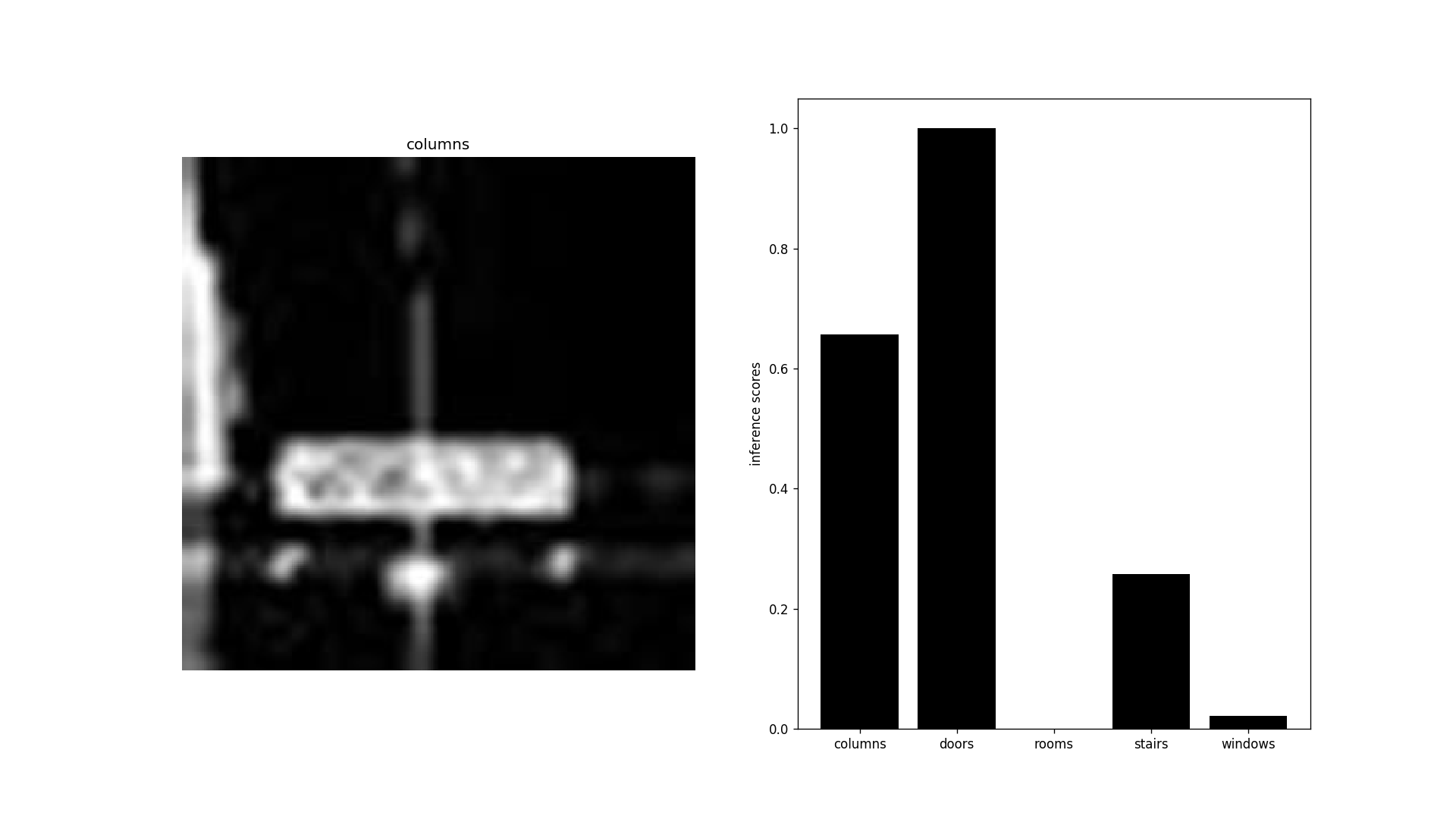
Some examples can be seen below of individual samples from the validation set being classified into one of the five categories. The images are quite low quality and the training set size was restricted by the time available to make them by hand, so this was considered a quite positive result in the ability to train a classifier to recognize these kinds of images in a sparse feature space.
Image: 1 of 6
Segmentation
As the goal was to operate on full building floor plans, once the classifier achieved a satisfactory validation accuracy, it was applied in a sliding-window pattern across whole unseen floor plans to try to classify each window into one of the known categories. The hypothesis was that the model would be able to produce semantic segmenations that could form the basis of an analytical technique that evaluated the qualities of the composition of various architectural elements.
Some examples of the target floor plans, segmentations, and confidence maps can be seen below.
Image: 1 of 8
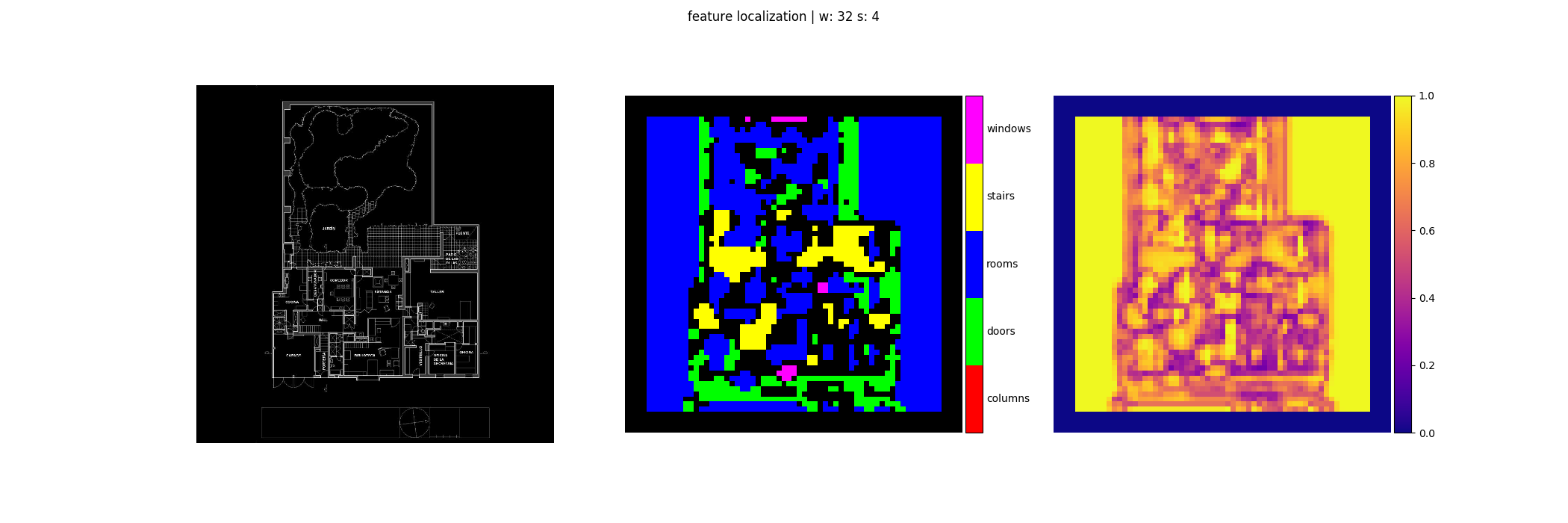
Several endemic failure modes kept this application from being successful. Notably, the lack of a feature indicating the difference of “image background”, “empty interior space”, “exterior space” results in huge swathes of many plans be segmented into the “rooms” category in many cases with ~100% confidence.
The lack of a validation set for the segmentations combined with these obvious failure modes meant that this experiment was a failure.
Autoencoder
In order to make use of the largest set of data available (unlabled, but feature-ful) floor plans, we turned to autoencoders to form the basis of an analytical model. The hypothesis was that the restricted “encoding” layer would could form the basis of an analytical system. I.e. qualitatively similar images would be closer in the encoded space, different images would be further apart, realistic construction drawings would be grouped together, while conceptual sketches would be grouped separately, etc.
The autoencoder operates on images at a resolution of 1024x1024 (or a 106 dimensional input space) in batches of 16 over 100 epochs using pixel-wise binary cross entropy loss and passing through a 100 dimensional encoding layer. By the end of the training period, the reproductions closely match the input, indicating that the model has learned efficient compressions of the feature space that are still able to capture the variation of the source space.
Below are the results of the same 16 drawings at every 20th epoch.
Image: 1 of 6

The high-quality reproductions indicated that this would be a suitable basis for an analytical tool that could be used on generated plans.
Generation
As originally proposed, once a suitable model was found (originally DCGAN), we began using the various data subsets to generate along certain qualitative vectors. The images were generated at a resolution of 512x512 in batches of 64 in order to balance image quality with batch size to prevent “mode collapse”, where the generator is optimized to produce only simple patterns rather than coherent imitations.
Le Corbusier
Using a dataset of drawings solely by Le Corbusier, a modernist known for advocating for minimal structure and mechanical architectural elements results in generated plans that are rather homogeneous.
Image: 1 of 3
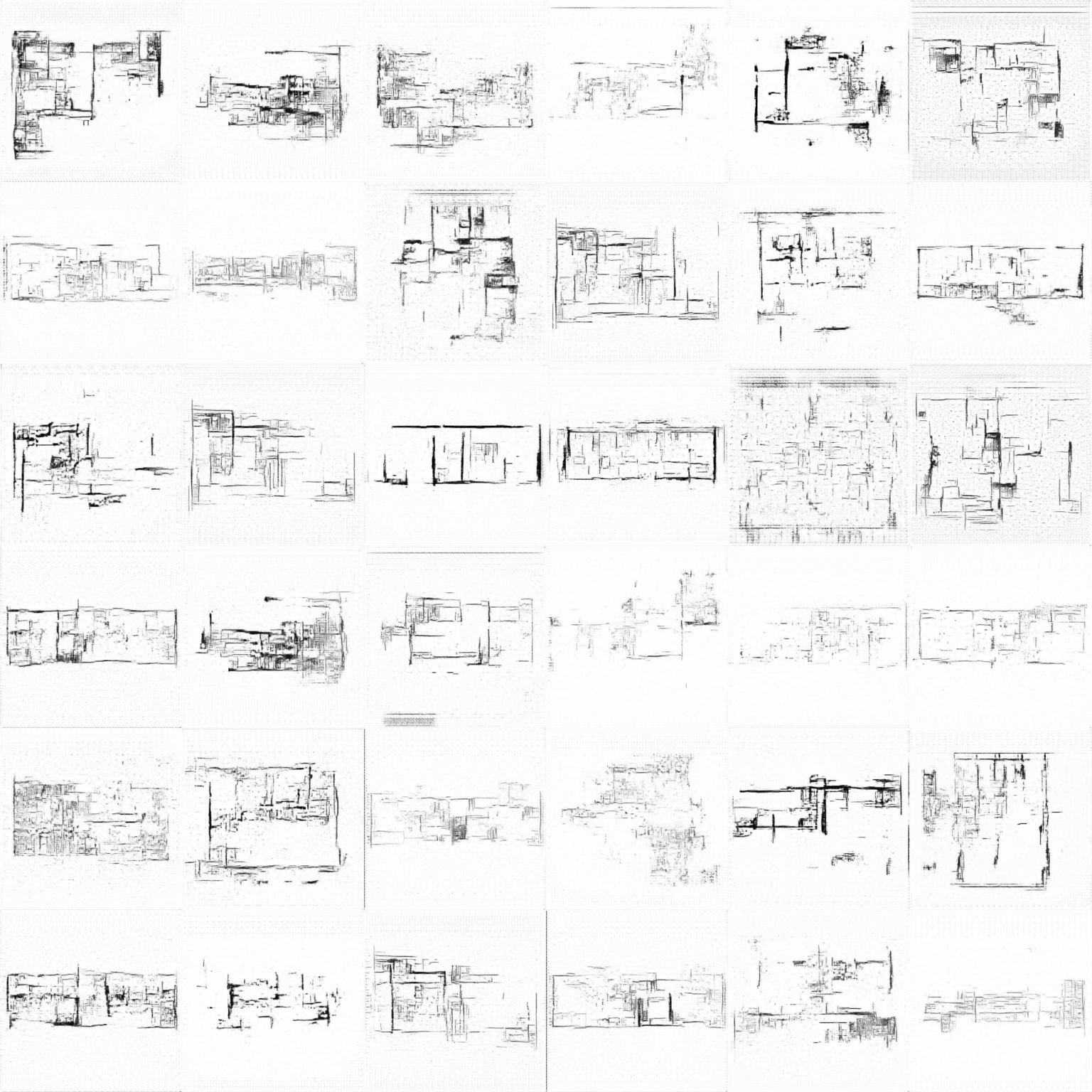
Michael Graves
Using a dataset of plans produced by Graves, a postmodern architect whose work is arguably the antithesis of Le Corbusier’s results in a less homogenous output as the generator learns to imitate the large-scale figural features of the building shapes. Though, the light linework and poche of the drawing styles is also imitated which creates a different kind of homogeneity.
Here, the more regular spatial organizations of the source material is more easily fit by the weights in the network than was accomplished on the sparse feature space of the modernist, free-plan philosophy of Corbusier. This makes the drawings more easily recognizable as “buildings” in a typical sense.
Image: 1 of 6

Morphosis
Moving forward in time to the work of the contemporary firm Morphosis, the diverse feature set and drawing styles result in a generated drawings that closely mimic the input dataset, while also producing hybridized features. Projects with similar scales have features like large diagonal walls, empty spaces, densely loaded corridors copied and combined as the generating function tries to efficiently get the discriminator network to recognize the drawings as “real”.
Types of plans also begin to emerge. U-shaped plans show up in multiple iterations, courtyard buildings appear with thicker and thinner boundaries, and simple rectangles are populated with different attempts at generating rooms and core configurations.
Image: 1 of 6

This was taken as a sign of success that the generative adversarial network could generate convincing architectural drawings, provided that the input feature set is diverse enough.
In order to expand on this, we began trying to “steer” the generated images by making unusual combinations of features using disparate datasets.
MorphoGraves
Combining the single-author datasets that produced high-quality imitations, Morphosis and Michael Graves, we continued the generation using a balanced comprised of 50% of the two authors.
Image: 1 of 6

The courtyard buildings from before reappear, but this time with attempts at smaller figural courtyards and the occasional tower. The U-shaped buildings occasionally lose an arm to fit the, now, more common bar buildings.
However, the moderate resolution of the images, combined with the scale of the rooms in these building types (many large hotels and institutional projects which are represented in only 512x512 pixels) allow the generation of many examples of incoherent, sketchy fields which are nearly devoid of architectural content.
Everything All At Once
In order to maximize the sampled feature set, the final dataset was comprised of the MorphoGraves set and, in even proportions, medieval castles and WPA buildings, simply to see what would result.
In order to maximize feature quality, the images are generated at 1024x1024 with a smaller batch size of 4. But, the network is trained as a GAN and an autoencoder that we refer to as AEGeAN.
Image: 1 of 6

The generated images are the most different from the source material, but many are barely architectural, appearing more like charcoal or ink conceptual sketches. Organizational structures are just beginning to appear like nested bar buildings with corridors and large, open rooms. But, paired with instances of almost completely abstract patterns, indicating the near mode collapse of the network as it tries to fit the diverse feature space efficiently at a high resolution and correspondingly lower batch size.
Conclusion
We found that it is possible to train a neural network to recognize architectural features given a small dataset of a sparse feature space. But, this classifier is not able to generalize well in a sliding-window application to entire architectural drawings. We found that we are able to train an autoencoder to replicate entire architectural drawings, even in a high compression ratio from input dimension to the bottleneck layer. We were able to train a generative adversarial network to replicate the work of individual architectural styles when given a diverse enough feature space to fit to. We were able to steer this generative approach simply by altering the proportion of styles or authors in the source dataset. We were also able to generate novel, though primitive architectural drawings by training on a large, diverse, and balanced dataset of many authors and styles when the network is trained in parallel as a GAN and an autoencoder in order to avoid mode collapse at large resolutions and small batch sizes.
- All source images copyright of their respective authors↩